Introduction
As an engineer, deploying your code to production is satisfying, but often, the satisfaction is preceded by anxiety, and in some unfortunate cases, followed with the chaos of rolling back a code change. At LiveRamp, in the pre-GCP days (check out LiveRamp Is Migrating to Google Cloud Platform), we had a Capistrano deployment system known as pentagon in our colocation datacenter that pulled in code from Git and deployed it to our fleet of virtual machines. We extended this deployment flow to our then-monolithic Kubernetes cluster by building a custom tool, kube_deploy_tools, internally known as kdt.
While this worked well for us, it wasn’t without its challenges, especially once we migrated to GCP and moved away from pentagon. Most notably, engineers started deploying to their Kubernetes clusters (we adopted the model of each team owning their own GKE clusters in a GCP project created by the DevOps team, managed via IAC) from their laptops. We still had audit logs in GCP logging indicating who deployed what and when, but accidentally deploying a local development branch to production wasn’t a far-fetched possibility. Rolling back when needed was again manual. We decided to use Spinnaker to address these challenges, and in this blog post we will discuss how we are using it along with Jenkins.
Design/Architecture
- In collaboration with the Quality and Reliability team, we agreed on the following deployment cycle:
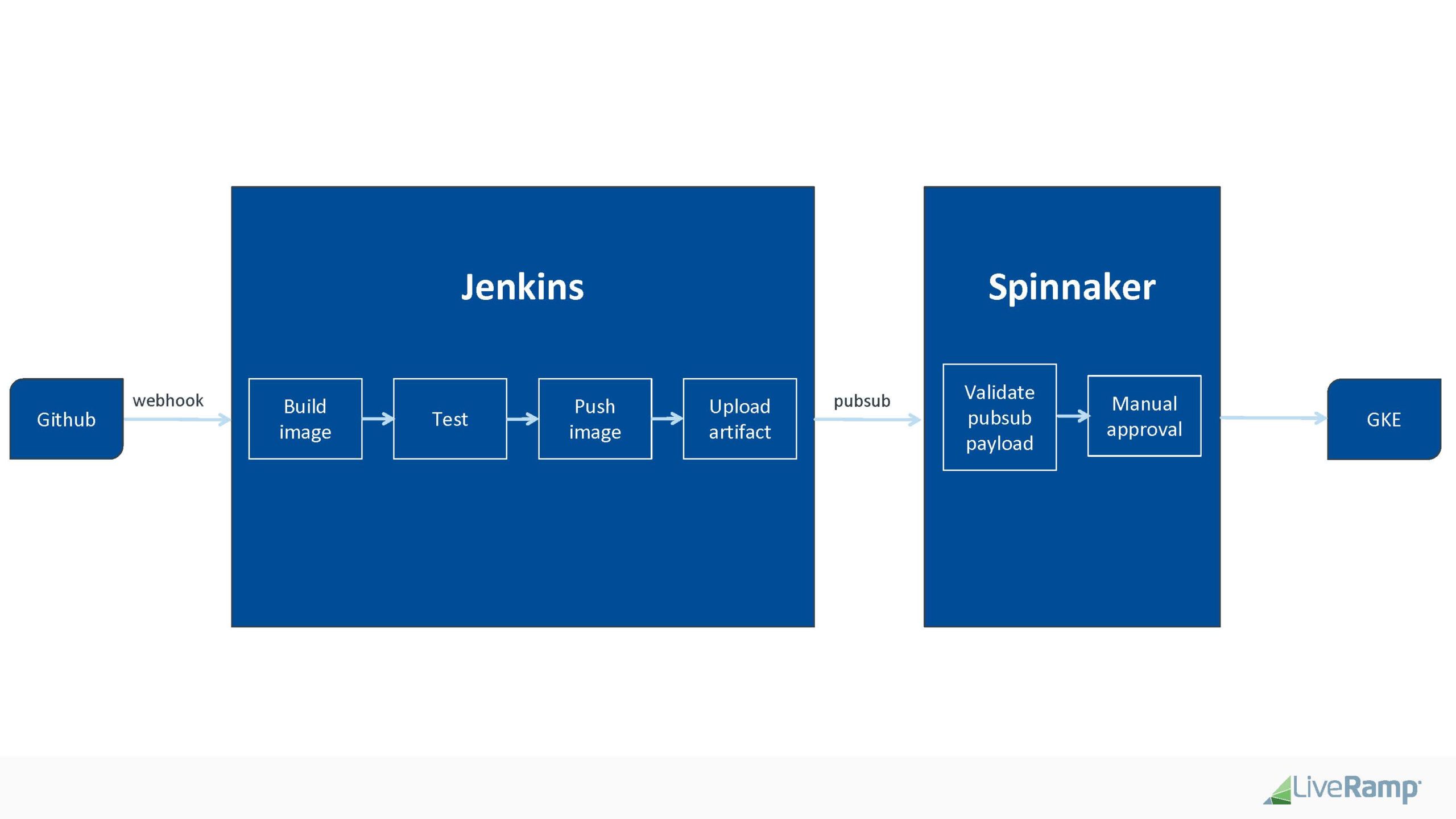
- Github pull request merged to master
- Github triggers Jenkins build via webhook
- Jenkins (CI):
- builds application container(s)
- runs app-level tests
- kicks off a functional test, integration test, performance test, etc.
- pushes the container(s) to container registry (GCR)
- generates build artifacts and uploads to GCS
- triggers a new event to a pubsub topic
- Spinnaker (CD)
- listens on this pub/sub topic and triggers a deployment pipeline
- The pubsub msg contains:
- Location of the GCS bucket of the Kubernetes manifest
- One or more key/val pairs that uniquely identifies the deployment pipeline for an application
- The pubsub msg contains:
- Wait for human approval notified via Slack channel by Spinnaker bot before deploying to a Kubernetes cluster
- listens on this pub/sub topic and triggers a deployment pipeline

- Access
- Spinnaker has a UI which is secured by IAP, which means as an engineer, you don’t have to worry about being on VPN
- Another layer of security we have is that deployment pipelines are controlled via Google groups Authorization, such that each team can only view and deploy their application
Implementation
A sneak peek into our Spinnaker setup:


Next steps
We look forward to sharing our code rollout improvements based on this new implementation with Spinnaker. In addition, we will be following up with a separate blog post discussing how we evaluated delivery platforms (Jenkins X, ArgoCD, Spinnaker and Harness) before deciding to utilize Spinnaker.