On Tuesday, July 20th, we held the first of our API-focused sessions of the LiveRamp for Developers series. This session was focused on the AbiliTec API and was presented by Kevin Wei, Lead Identity Product Manager at LiveRamp, and Adam Isom, the AbiliTec Backend Engineering Lead.
Attendees got an overview of the concept of identity, as viewed by LiveRamp’s product and engineering teams, and the logic behind the AbiliTec Graph. These build up to the foundation of the AbiliTec API, as well as the inputs and outputs the API utilizes. Lastly, Kevin and Adam gave a demo of the AbiliTec API in action.
Defining Identity
From the LiveRamp product point of view we can’t define identity without talking through its two most important dimensions; representation and perspective. Representation is a relatively simple topic, where someone’s identity is represented in many different shapes and forms.
For any given person, their identity is represented by a combination of names, historical addresses, third party cookies, customer account numbers, and so on.
But when we bring in the concept of perspective, it gets pretty complicated pretty fast. Not only are incomplete representations collected at different times by different companies – so think publisher sites, loyalty lists, adtech platforms, etc. – but everyone has their own custom business rules about how to treat identity.
If you layer these two concepts of perspective and representation, we arrive at this kind of world where different representations infinitely are scattered around in near infinite amounts of perspectives. Since LiveRamp’s mission is to make it as easy as possible for companies to use their data effectively, we need to make sure we talk in the same language, and identity resolution is the tool we use to do that.
And so from the product perspective, while there is some platonic ideal of identity that you know is perfectly represented by objective reality, we don’t assert to be perfect, but we try to get as close as possible. And all of this starts with the AbiliTec API.
Our client base extends across different applications, platforms, companies, ecosystems and industries. But the problems are still the same for any company who interacts with a customer; it is faced with fragmentation and outdated data. From what we’ve seen, marketers use an average of 12 platforms in their stack. And we’ve seen typically up to 2% of their own CRM changes each month, due to marriages, moves, name and contact changes, etc.
That equates to approximately 24% of any company’s CRM that will be out of date across a year. The manifestation of all of those kinds of changes ultimately adds up to a poor customer experience; whether you’re serving an ad for something a customer has already purchased, or you’re incorrectly targeting someone because you have the wrong context around them.
AbiliTec is meant to solve those huge vast identity resolution issues through three main use cases for “offline” data files. The first; it can be used to unify data assets that are key to different types of directly identifiable data (DID). For example, if you have a bunch of files and data tied to email and postal files you need to de-duplicate them and improve consolidation.
Secondly, it can also be a key component for record enrichment. Not only are we building a marketplace of offline data providers that can append demographic data to customer CRM using AbiliTec to link, but we’ve seen use cases where customers have used AbiliTec IDs as a primary key to share data between businesses without sharing the exact DID.
And the third, is that you can dedupe and hygiene a ton of datasets using AbiliTec which ends up improving your data fidelity for onboarding. For anyone who’s using LiveRamp’s onboarding products, this provides an optimized experience through that process.
The AbiliTec Data Graph
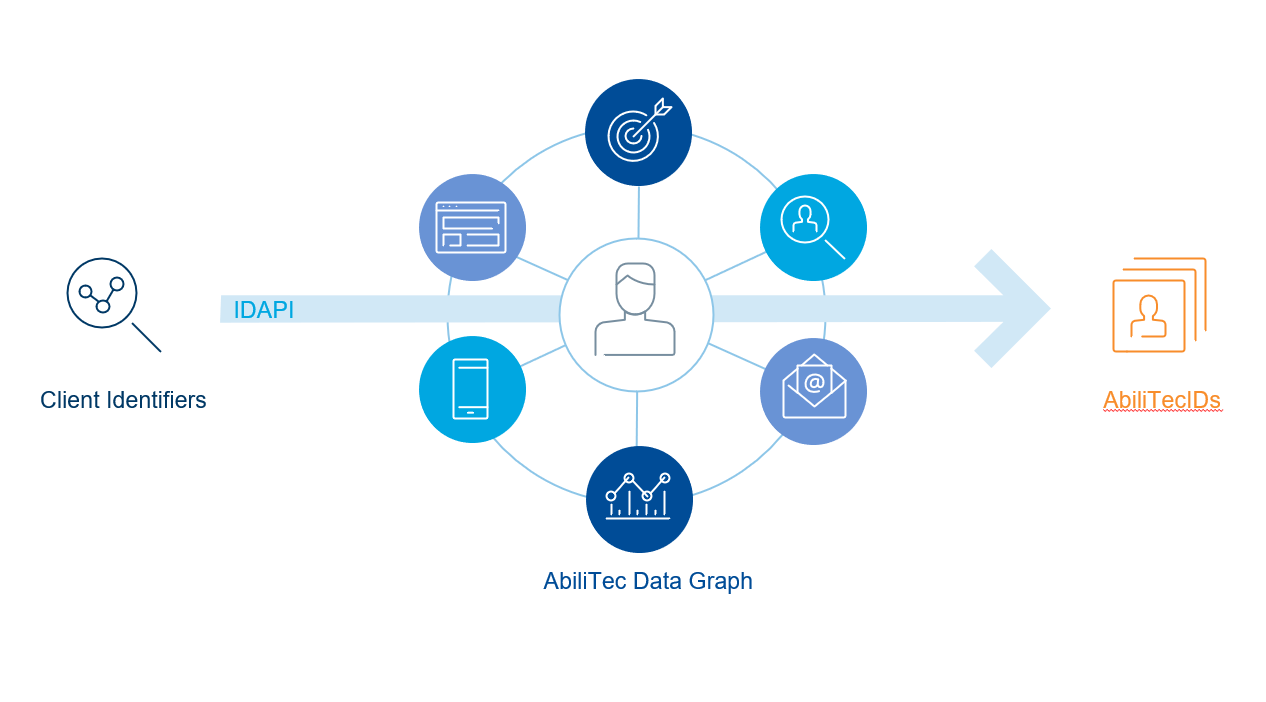
When we talk about the AbiliTec API it’s really just the access layer for the underlying AbiliTec Data Graphs. And so just for a brief primer on the API it’s broken down into three parts:
- you submit input PII and so since we’re in the offline world you can think of that as email addresses phone numbers and postal addresses.
- the API takes in that request through some black box magic
- we return AbiliTec IDs out of the API.
Output is generally an identifier that our customers can use to analyze their data sets and connect to the rest of the ecosystem.
Before we get into the API there are a few key AbiliTec graph concepts that will be necessary to understand how the API works. First the graph itself. We define a graph as a collection of organized relationships. It’s often discussed in terms of nodes, which are points on the graph, and then edges, which are connections between the points.
The key concepts covered are: how we build a graph, what it means to be non-discoverable, stats about the graph itself, and then some key identifier concepts which will ultimately build into the understanding of the API.
To form an identity graph the LiveRamp AbiliTec team ultimately needs two things: data, and our consolidation algorithms. In terms of data, LiveRamp obtains data from over hundreds of sources, updated almost every day, and these data sources ranging from public records, aggregators, niche data sources, and consumer files. But all this raw data though is ultimately useless without a solid foundation to actually parse and derive logic from it.
LiveRamp’s data graph team has more than 20 years of experience refining the “secret sauce” to have the most accurate representation of reality as possible. The consolidation algorithms take in various factors such as observed frequency of data, historical graph decisions, and source credibility, among others, to come to the best possible conclusions. And we rebuild our graph every month so we can have the most up-to-date representation of reality.
The second concept is non-discoverability; one of our competitive advantages in terms of coverage and accuracy. So non-discoverability means that LiveRamp will never sell, monetize or expose the DID we actually used to create our graph of relationships. LiveRamp does not do any sort of contact appends, since our non-discoverability principle means no email appends, no address appends, name appends, etc. So from the API you’ll never receive any DID information that you don’t already have.
One of the main benefits of that is that as a result of being non discoverable we have a ton of unique data graph contributors and better scaling accuracy. Since we constantly rebuild our graph, with more and better data and more unique data, we create a flywheel of a better understanding of identity.
I think the things to highlight are ultimately that we have billions and billions of representations that expand across 45 years of historical data. For any of our customers who are primarily coming through onboarding , this is ultimately the foundation for how we were able to achieve our scale and accuracy in the online world.
- We can tie an average of 12 historical and current pieces of DID to individuals in the strong parts of our graph
- There are more than 4 billion records, including 2.5 billion email addresses alone
- All gathered data historically spans close to 50 years, since 1973. This significantly strengthens our graph and is unparalleled.
- The robust API-access mechanism, which can handle robust production throughputs
- Most importantly, it is the core of LiveRamp’s online graph, so normalizing data using this identifier will improve identity throughout LiveRamp’s RampID ecosystem
The Foundation of the AbiliTec API
Returning back to the original goal of identity resolution and AbiliTec – to describe individuals, representations, and their relationships – it’s helpful to understand the logic of how we build our graph. If we define an individual or want to find an individual from a way that we can actually scale that definition, our graph actually needs to create a few intermediary concepts to get there.
The concepts discussed so far, and the following concepts are going to be critical to actually understanding what can be input into the API, and what the results from the API will deliver. One of the foundations of an individual from our perspective, is a touch point. A touchpoint is simply defined as an identifier, without a name, and since we’re talking about the “offline world” there’s three kinds of touchpoints:
- postal address
- email address
- and phone number
But conceptualizing or summarizing an individual with a collection of touchpoints can be difficult. And that’s because the reality is that it’s near impossible to just use touchpoints to summarize or identify a person because touchpoints can be shared across multiple people and multiple points in time. To solve this problem we utilize the concept of entities, which are just touch points with names. And really entities are just touch points with names.
The AbiliTec graph actually has a bunch of logic such that if you give us just a postal address we’d be able to give you – based off of the billions maybe trillions of data points – who we think is the best person for a given touch point.

And so entities then become the building blocks for AbiliTec identifiers. If you think about touch points and entities as an input to the API, AbiliTec IDs are ultimately the output. The main Abilities IDs out there are consumer links, which represent an individual household link, made up of a collection of individuals, and an address link which is a unique identifier or even place.

And this is all to illustrate what the graph is composed of, or how to best how I visualize it. And there are three main distinct regions of the graph. At the top left cluster you’ll find these specific acronyms: NAP stands for name and postal, NP stands for name and phone, and NE stands for name and email. So the top left cluster, where you see 3 nodes connected, would be considered as one individual consumer link.
Moving to the top right, that would also be considered as a separate consumer link. The dotted line could be considered a household since those individuals are connected by sharing a name and postal. And at the bottom, we see a super-connected individual; which means we have a bunch of representations for this given person; multiple name and postal addresses, for example, which are connected by name and email entities, name and phone entities, and so on and so forth.
We talked a lot about the kind of the buildup to and really the inputs to the API, and now we’ll focus on the actual links which have a lot of associated metadata without them. First, if you look through the first four alphanumeric strings, the output that we return to customers is customer-encoded with their own four alphanumeric digit domains.

So the consumer link that represents a person would look completely different to two separate API users. The reason we do that is to ensure that there isn’t a universal ID that describes an individual, and preserves the security of a link. There’s a country code, and then what’s really important is this concept of link type.
We generate two kinds of IDs from our API, and if you work in the RampID space you’ll also kind of recognize this, there’s two kinds of link types: we generate a maintained ID, or maintained link, when an input piece of DID matches to a node within the AbiliTec knowledge base. These can help a client consolidate or link data. So let’s say if you sent in an email address through the API and we recognize that you know that email address is also within the AbiliTec knowledge base and graph, then we return something that begins with the digits 0.
On the other hand, in the case that we don’t have that representation, entity, or touch point in a graph, we’ll return a derived link. Ultimately what that means is that we don’t recognize it within our knowledge base, and will return a derived link. A derived link represents an entity that is not recognized in the graph. Derived IDs are algorithmically derived based on input data — upon the same entity input, the API will consistently output the same derived link. The use case for a derived link is to maximize connectivity even if an identifier is not recognized by the LiveRamp graph. This allows clients to still join on input data sets for consistent linking across files.
We talked about inputs to the graphs such as touchpoints and entities, but now we’ll focus on the outputs, and really what you would see as an AbiliTec API customer. We generally refer to output collections as data bundles, and individual components as elements. The API will always generate a consumer link, address link, and household link, for whatever input data that we receive. And we generate the format of those links. We’ll also generate a set of match metadata, which is a collection of data of how we match to the input data, and how we got to a singular link. The match confidence is given as an enumeration of match components. You can find more details on what that looks like in our Developer Portal, and specifically within the AbiliTec API documentation.
The last thing that to mention and one of the other use cases that we’ve seen a lot of customers use – is that they use AbiliTec IDs and links to communicate with LiveRamp and other customers because it’s a near perfect representation of an individual. But when you send data to the API we don’t log or store any of what is sent to us. And is very secure as it really exists only in memory; it exists for ~100 milliseconds and then is immediately gone.
So for customers that don’t want to give LiveRamp DID, or have security concerns about giving LiveRamp DID, we often offer the AbiliTec API as a way to communicate with LiveRamp without losing a ton of fidelity.
A Demo of The AbiliTec API
In the session, participants also got to see a demo of the AbiliTec API in action.
Next Steps
If you’re interested in learning more about using the AbiliTec API, as well as the answers to some of the questions discussed in this recap, you can check out the session on demand, by registering. In addition, if you’d like to take a deeper dive, please reach out to us via the contact form, to get in touch with experts that can lead you through discovering your specific challenges, as well as the solutions we have to offer.
I encourage you to take a tour of the portal and view the upcoming sessions, which will be focused on individual APIs. They will be led by our product managers for each of the APIs and their engineering counterparts. Also, take a tour of the portal, so you can understand how the APIs can be utilized. There will be Q&A at the end of presentations to allow you to get your questions answered by the teams actively working on the APIs.
Lastly, the best way to stay up to date on LiveRamp’s offerings, from data science to APIs, and beyond, is to subscribe to our engineering blog, which you can do below.