Copying to the cloud
LiveRamp is in the midst of a massive migration of all of our infrastructure to GCP. In our previous posts we talked about our migration and our decision to use Google as our cloud. In this post, I want to zoom in on one major problem we needed to solve to pull of this migration: copying our data into the cloud.
LiveRamp occupies a relatively niche area among big data companies: our entire product is powered by big data jobs that are reading and writing hot data. We do have some relatively large historical datasets, but these are a secondary concern compared to large data sets that we generate and use immediately, and which we expect to keep for only a few days. Because of our data access patterns, most solutions for cloud data migration were poor fits – in particular, data transfer services such as Amazon Snowball or Google’s Transfer Appliance were essentially useless to us.
To further complicate things, the colocation facility from which we are copying all this hot data has a fairly old network designed primarily for intra-network data transfer. Hardware upgrades could cost hundreds of thousands or even millions of dollars, and so we’ve had to make do with what we have – we stretched the hardware to the max to get 50 Gbps of Interconnect throughput to GCP. The mandate of our data infrastructure team was to build out tooling to make it possible for our app developers to share this limited resource and get their data into the cloud without interrupting service to our customers.
The Data Replicator
The application we built to meet these needs is called the Data Replicator. At its core, the Data Replicator is a vehicle for running the DistCp hadoop job built into most Hadoop distributions, but surrounding that core are some complex problems touching on distributed job scheduling, monitoring, and obeying the principle-of-least-surprise that I’ll discuss in more detail.
Architecture
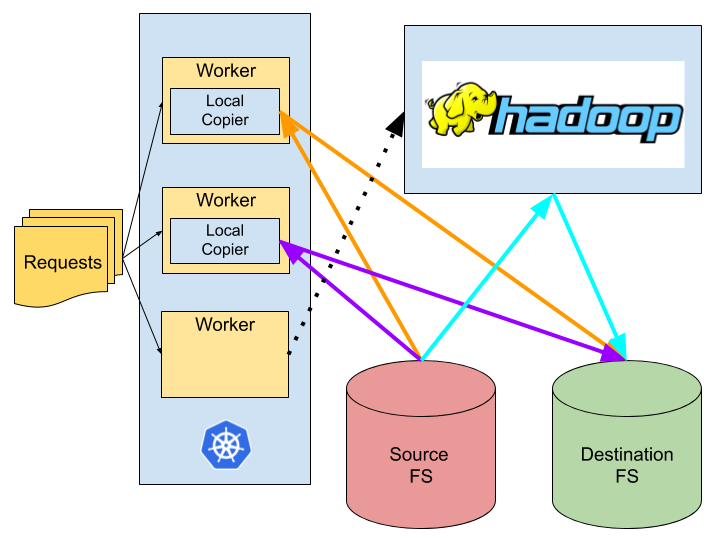
We use LiveRamp’s daemon_lib project to orchestrate a fleet of Kubernetes pods which pull from a queue of submitted data replication requests, each request containing a source file path and a destination file path. We check the size of the source – for small datasets, we use the local process to copy the data to its destination, while for large datasets we submit a Hadoop DistCp job to our Hadoop cluster to perform a highly distributed copy (more on this later).
Database as Priority Queue
Like so many applications in the wild, the Data Replicator can be modeled as workers taking tasks from a queue and executing them. We do not however use any of the typical distributed queue solutions that exist, such as Google’s Pub Sub or Apache Kafka. Instead we handle requests using plain old SQL. This gives us a few advantages:
Data Replicator jobs can run from anywhere to 30 seconds to 24 hours, and we wanted to minimize the chances that we return any kind of failure to a user (or, even worse, that a request is dropped). That means we need significant durability and “acknowledgement” features — items are “removed” only when the work is done, not when processing starts. A request life-cycle looks something like this:
Most distributed queues have poor support for ensuring items get processed when processing can take such a long time, or workers can die mid-job. If an executor dies mid-job, the request is marked as failed, and either kicked back to ‘pending’ or manually cancelled.
Likewise, a primitive request queue gives limited visibility into states of long-lasting requests. We want to give both human and software clients a clear view into system state. Because this is just SQL, we can index on whatever we need to provide this visibility to either external applications, the UI or executors:
Specifically, the executors want to choose the highest priority pending request. Most queues do not cleanly support reaching potentially thousands of items back into the queue to grab a high priority item. Our index acts here as a priority queue to keep this query cheap:
This careful indexing gave application teams the freedom to submit hundreds of thousands of low-priority requests without degrading system health:
Last (but just as importantly) our devops team and our devs understand SQL and MySQL pretty well – learning a new technology and building out the surrounding features we’d need to use it represents a big opportunity cost. By sticking with SQL, we were able to best leverage the talent already available on our dev team.
We use LiveRamp’s daemon_lib project to orchestrate the process of checking the database, marking items as picked up, processing them, and then marking them as complete or failed. We use locks built with Apache Curator and Apache Zookeeper to coordinate processes as they read from and update the db. We also use Curator ephemeral locks to register work being done so that if data replication jobs die in some unclean fashion, this will be detected and other works will return that work to the queue. All together this gives us a super resilient system that ensures we’re doing the right work at the right time and that nothing gets lost.
To be clear — we did not build this daemon service infrastructure just for the Data Replicator. daemon_lib and database-backed queues are used widely within LiveRamp, and our existing tools helped us quickly build a fault-tolerant system out of the box.
Monitoring
Visibility into system health was a driving design goal of our service. What we got out of the box by using LiveRamp’s internal service processing framework was a nice UI showing a summary of Data Replicator requests:
While this gives us a source of truth on system health, at LiveRamp we prefer to use datadog dashboards to build time-series UIs, so we decided to push as many metrics as possible to DataDog and build comprehensive monitoring there. We pull data from a variety of sources:
- We’ve written before about how useful MapReduce counters are when debugging MapReduce jobs. Distcp is a MapReduce job, so we push the interesting ones to DataDog.
- Because our work queue is easily queryable, we push metrics about the pending work queue to DataDog.
- Executors themselves push metrics about the files they are copying.
- We pull Cloud Interconnect utilization metrics from the GCP API
Here are some of the more commonly referenced charts we have built:
This is the most basic metric about system health — show the size of our work queue. If we have no pending or failed requests, we are in great shape.
Of course, raw count is a crude metric. We support request priorities so teams can submit huge backlogs of low-priority cold data replication without impacting high-priority traffic. By tracking request time per priority, we can check that time-sensitive requests are actually getting processed quickly:
Our most important system limitation is bandwidth. We track historical utilization of our interconnect bandwidth:
This gives aggregate utilization, but does not decompose it by application. Because individual requests are tagged by client application, we can actually attribute bandwidth utilization to service consumers:
With these tools, we feel very good about our visibility into the health of our Data Replication service.
The Trouble with DistCp
An interesting interface problem we hit with using DistCp was with DistCp’s overwrite option. The overwrite flag controls what happens when DistCp detects that a file it is trying to copy already exists on the destination file system – if overwrite is false, DistCp does not copy the file, and if overwrite is true, it deletes the file that’s already there and copies the source file.
DistCp does not check the contents of the file in any way, so it’s important for users to understand when their data may or may not be fresh, and thus if overwriting is required. We wanted to allow our consumers to set this flag themselves for cases where they may not want to keep track of whether a dataset has been copied before, and want to do the most efficient operation in cases where they may request re-copying of data which has not changed.
We hit a snag though – as outlined in the docs for DistCp, the overwrite flag actually changes the directory structure of the data that gets copied! We debated simply informing our users of this “gotcha” and having them account for it in their requests, but we decided that this would be a huge violation of the Principle of Least Surprise, and would ultimately cause more pain to our users and our team than accounting for this quirk and having the Data Replicator behave the same in all cases, even if DistCp does now.
Adding the code to “wallpaper” over these inconsistencies in DistCp involved some branching logic, but was ultimately not as complicated as we feared. What was hard was verifying that all the cases we wanted to cover did, in fact, behave in exactly the same way. To test the new code, we wrote a single, extensive test using LiveRamp’s generative library to create 100s of combinations of potential inputs, and verifying that the created files and directory structures were what we expected. We’ll write more about our experiences with generative and property-based testing in a future blog post.
Jobs of Every Size
To keep the user interface simple, it was important that the Data Replicator presented users with the same API for copying both small files and large files — a user wanting to copy 5TB of cold data used the same service calls as a user copying a 5MB import.
While MapReduce — and thus DistCP — is perfectly happy to launch a YARN application to process a request which only copies 5MB of data, launching a YARN application incurs a fairly high overhead cost: if a 5MB copy job is submitted to the ResourceManager, an ApplicationMaster is launched, and a single (short) map task does the actual copying:
To avoid this unnecessary overhead, we drop tasks down to “local mode” when the input files for a request are < 1GB. In this mode, workers copy data directly from the source FileSystem to GCS, without launching a DistCP application:

Local mode was highly successful at reducing system overhead; in fact, 75% of our requests skip DistCP entirely, copying directly via the worker:
The last bottleneck we hit actually related to our ability to launch jobs quickly enough. While pulling work off of our queue, a worker ends up “locking” the queue for a couple seconds while building the request. At extremely high request volume, with tiny requests, this can become a bottleneck on throughput. We solved this by “sharding” work across executors within the [Status, Priority] queue and independently locking shards:
With this in place, we were able to process as many requests as necessary to handle application demands.
The Future of the Data Replicator
At LiveRamp, we love writing code, but we love one thing even more — deleting it when it is no longer useful. While we are proud of the Data Replicator service, it won’t be a permanent installation — we are migrating entirely to GCP, and once we are there, we won’t have any of the bandwidth limitations we built this service to manage.
The last three posts have mostly talked about how to transition our existing infrastructure to GCP. In our next post, we’ll talk about the most fun part of being on GCP — getting the opportunity to rebuild systems using cloud-native technologies. If that sounds exciting, remember, we’re always hiring.