The fundamental challenge being solved is aggregating and counting the unique values in a large multiset. Here is a matrix visualization of one dataset: 
The goal is to be able to retrieve counts of unique IDs with different constraints. For example (using SQL-like syntax to illustrate), computing COUNT (DISTINCT ID) WHERE (Field 1 = 0) or COUNT (DISTINCT ID) WHERE (Field 2 = 1).
The datasets being operated over are unstructured and stored as sparse row records containing an ID and one or more data fields. They are ephemeral and frequently change, so they are not indexed.
There are additional properties and constraints of our datasets that make this problem much more difficult and much more interesting.
- Datasets range from being very small to having 10’s of billions of rows and 100’s of thousands of columns. Raw storage size can be in the 10’s of terabytes when serialized and compressed on disk. It would be prohibitively expensive to use any in-memory database or storage solution.
- Datasets change regularly and are deleted regularly. These stats are being computed on intermediate datasets in our pipeline that are frequently changing and too large to keep for long.
There are several properties of our business that make this problem easier, however.
- Reports are not needed in real time. It is acceptable to respond hours after the dataset is created.
- Exact counts are not necessary. Bounded error is acceptable, so estimation techniques are possible.
- The aggregation and queries that we support are fixed for each dataset. Therefore, we can process all possible queries in batch and cache the results, allowing us to delete the underlying dataset. (The supported queries are essentially limited to querying for a value in a field. For example, WHERE Field 1 = 0).
Given these constraints, we opted to take a batch approach to compute all supported stats for a given dataset, then cache the results in a relational database.

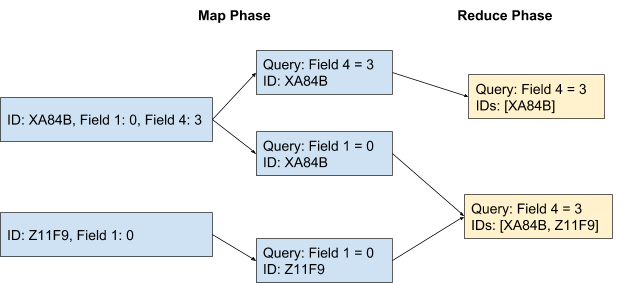
A MapReduce job is run over the dataset. In the map phase, for each record it is determined which queries it meets based on the fields of data that are present. An output record containing the ID, and the query, is output for each query the input matches. The reduce phase groups records for the same query together, and counts the number of unique IDs that are present. We then take the counts for each query, and add them to a cache in a relational database.
There are two major scaling challenges presented in this approach. First, the IDs present for each query in the reduce phase are not necessarily unique, and there can be potentially billions of them. Second, the map phase is expanding out the number of records into all of the queries they satisfy. This is bad because it leads to an enormously expensive shuffle.
The first problem can be solved entirely by using the HyperLogLog++ (HLL) algorithm. (HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm). HyperLogLog++ defines a small, fixed size data structure that can be used to accurately estimate the cardinality of sets with trillions of records (or more). An HLL provides a data structure similar to a set, and supports adding new elements, merging two HLLs, and retrieving the current cardinality. Both adding values to an HLL, and merging HLLs are commutative and associative operations. We can therefore construct a single HLL for each query, rather than track all IDs associated with the query.
The second challenge is integral to the batch approach, and ultimately cannot be entirely solved. To process all Q queries over the dataset, the work must be expanded out by a factor of O(Q) in the worst case. This places an unavoidable limitation on this approach as the number of queries grows.
However, it is possible to deal with this scaling concern more optimally. The most expensive part of the MapReduce process is the shuffle. In this case, if there are N records and Q queries, the shuffle must sort and distribute O(NQ) records. With the use of MapReduce combiners, the output records can be grouped by query on the map side. A single HLL can be populated for each query on the map side. The HLLs from each map task for a given query can then be merged together in the reduce phase. The requirement to use combiners correctly is that the reduce function is both commutative and associative. Adding values to an HLL and merging HLLs are commutative and associative operations. By utilizing combiners in this way, the map phase still must process O(NQ) records, but only O(Q) HLLs pass through the much more expensive shuffle phase.
This approach has been in use at LiveRamp for several years, and is currently used to efficiently process results for ~200,000 queries per day averaging ~15 million unique values per query. Datasets with billions of records and thousands of queries have been processed, resulting in 100s of trillions of expanded rows in a single MapReduce job.